

How to productize your machine learning model using Scikit-learn? [1/2]

“IT leaders responsible for AI are discovering ‘AI pilot paradox’, where launching pilots is deceptively easy but deploying them into production is notoriously challenging”.
Chirag Dekate, Senior Director Analyst, Gartner
VentureBeat reported that 87% of data science projects never reach production [1], and Gartner predicted in 2018 that by 2022, 85% of AI projects would yield incorrect results [2]. This represents a significant waste of effort and resources.
The challenges reflected in these statistics are varied. The requirements for a successful production deployment—such as team expertise, business knowledge, infrastructure, data and model pipelines—are complex and difficult to create.
In this post, I will highlight one crucial step for deriving real business value from machine learning: transforming a Jupyter Notebook model into production-ready code. First, let’s explore why using Jupyter Notebooks in a production environment is not recommended.
Why is this transformation important?
Model developers often create quick-and-dirty code in Jupyter Notebooks just to get it working. This code is typically inefficient and may require refactoring to avoid wasting time and resources during preprocessing in a production environment, which can be very costly.
Jupyter Notebook is a flexible interface that allows users to configure and arrange workflows in data science, scientific computing, computational journalism, and machine learning. It offers a simple, streamlined, document-centric experience and supports over 40 programming languages, including Python, R, Julia, and Scala. However, it’s not the best option for machine learning production code. Why? Let’s first define the requirements for production-ready machine learning code.
Jupyter Notebooks integrate Python code and Markdown, which is advantageous for data professionals developing their solutions. It makes it easy to document, explain decisions, and organize parts of the code. However, these advantages are not the focus for production code, which needs to be:
- Versionable
- Testable
- Manageable
- Integrable
1. Versionable
By versionable, I mean suitable for a Git-like workflow. Given that data, model parameters, and hyperparameters can drastically affect a model’s results, it’s crucial to ensure that every modification is tracked and any mistake in a new version can be undone.
To facilitate reproducibility, it’s a good practice to maintain a historical record of all relevant changes that can impact model performance [3]. Thus, it’s important to include in your Git-like workflow:
- All dependencies
- Random seeds
- Data and metadata used
- Model parameters
- Hyperparameters
- Outputs
2. Testable
With so many factors that can impact a model’s predictions, data scientists and machine learning engineers need to ensure that every step in the model pipeline can be tested. This includes validating any processing step in the data and code both before and after model predictions.

3. Manageable
By manageable, I mean the ability to easily reuse, improve, and correct parts of your system. This emphasizes the importance of modularity and the “Don’t Repeat Yourself” (DRY) principle. It’s likely that parts of your code will need to be used in different parts of your system, and utilizing functions and object-oriented programming makes this easier. Below, I show two different approaches to engineering a feature called city_revised in a pandas DataFrame, demonstrating more manageable versus less manageable code:
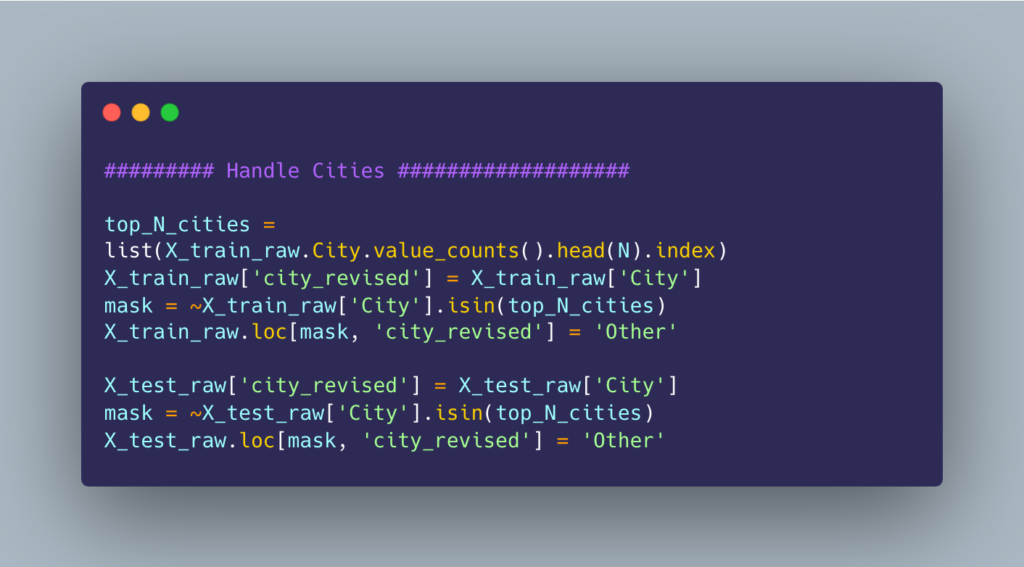
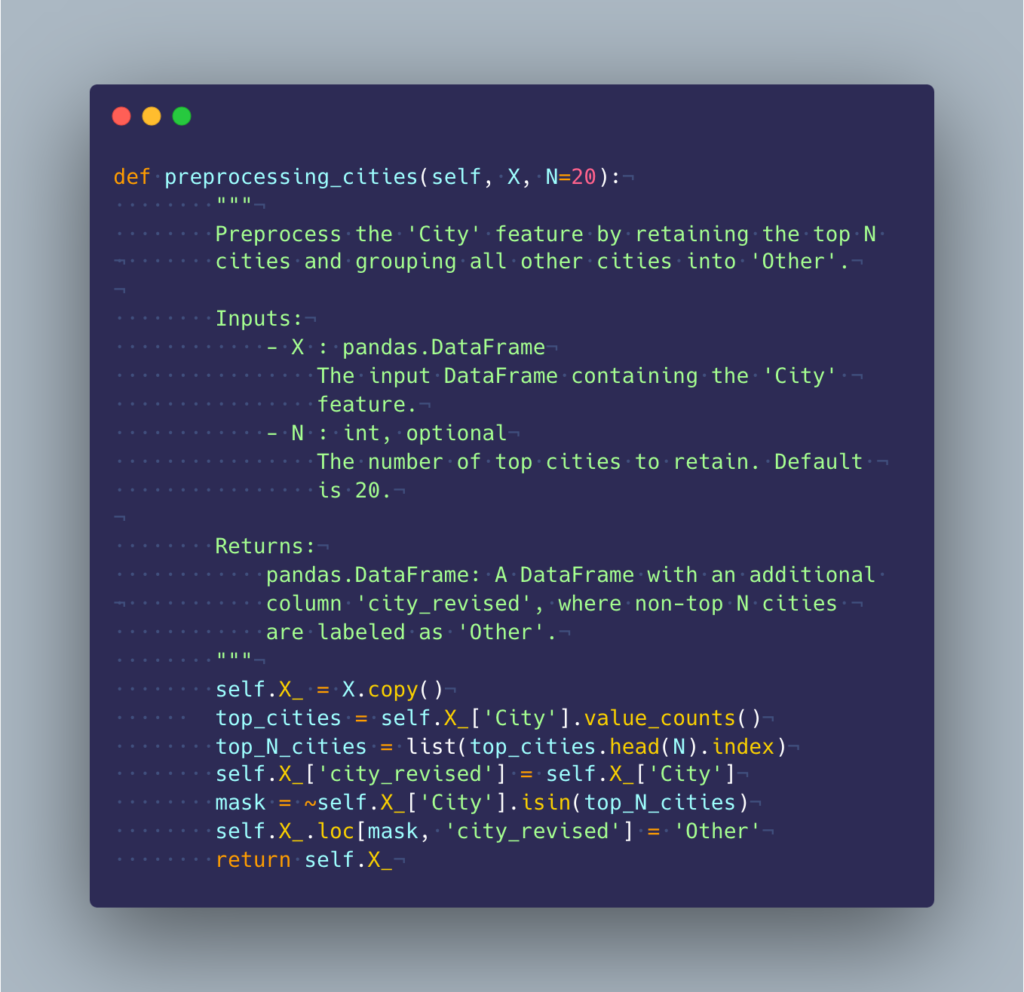
4. Integrable
Another important characteristic of production-ready machine learning code is that it should be easy to integrate. Improvements, changes, and corrections must be facilitated to occur frequently, avoiding unnecessary resistance. Therefore, it’s crucial to have an environment where your system supports continuous integration (CI) and continuous delivery (CD). However, achieving CI/CD with models and pipelines in Jupyter Notebooks is very challenging.
By transforming your Jupyter Notebook code into a more structured and modular format, you enable smoother integration processes. This setup allows your code to be:
- Automatically tested and validated with each change
- Seamlessly deployed to production environments
- Easily updated and maintained over time
Adopting best practices for version control, modularity, and automated testing and deployment can significantly enhance the manageability and integration of your machine learning projects.

In the next part of this series, I’ll present a method for creating a machine learning pipeline ready for production using Scikit-learn’s Pipeline and CustomPipeline, with specific methods tailored to your business case.
Feel free to share your thoughts, suggestions, or corrections, and don’t hesitate to reach out if you need further assistance when you’re ready to dive into it.
References
- VentureBeat. (n.d.). Why do 87% of data science projects never make it into production?
- Gartner. (2018). Gartner says nearly half of CIOs are planning to deploy artificial intelligence
- Burkov, A. (2020). Machine Learning Engineering.
![How to productize your machine learning model using Scikit-learn? [2/2]](https://rodolfoteles.com.br/wp-content/uploads/2024/06/Gemini_Generated_Image_2f1kr12f1kr12f1k-1-768x768.jpeg)

One Comment