
Model deployment patterns: Static deployment [1/4]
To provide business value and achieve real-world benefits, a crucial aspect of delivering a machine learning system is model deployment. Deploying a model involves making it available to accept queries from users of the production system [1]. Models are developed in a research environment and deployed in a production environment through the model deployment stage. The main goal is to achieve the same results in the production environment, where the model will receive new, unseen input data.

Development Environment vs. Production Environment
An environment refers to the configuration or state of a computer system where software or other products are developed, tested, or deployed. It encompasses the hardware, software, and network settings necessary for these activities. [4]
The development environment is the setting that contains the tools, programs, and resources suitable for data exploratory analysis and model development.
In contrast, the production environment is the live setting where programs run and hardware is set up to support an organization’s daily operations.
In this series, we’ll explore the four main model deployment patterns commonly used by companies.

Learning objectives
- Understand the importance of model deployment and its main challenges.
- Comprehend the pros and cons of the static deployment pattern.
- Visually recognize how a static deployment looks like.
Challenges related to model deployment
Deploying a model involves several challenges [4], including:
- Deciding the best deployment pattern based on team knowledge, resource availability, and deadlines.
- Ensuring the training dataset can be reproduced, especially when it is constantly updated or overwritten.
- Addressing situations where a feature used during training is not available in the live environment.
- Managing discrepancies between production data distribution and the distribution used during training.
A model can be deployed in several ways. To help you decide which pattern is best suited for your case, it is important to deeply understand each approach.
Let’s start by comprehending the simplest pattern: static deployment.
1. What is Static Deployment?
Following the same architecture as traditional software deployment, where the monolith architecture involves designing software as a single-tiered application with multiple components combined into one large application [2], the simplest and most straightforward machine learning deployment pattern is the static deployment.
In static deployment, the model is converted into an installable binary of the entire machine learning system. This means the model is packaged as a resource available at runtime [1].
Based on the data team’s choice and the execution environment, the trained model and features extractor can be converted into different types of packages, depending on where the entire software will run. The main options are:
1.1. Windows
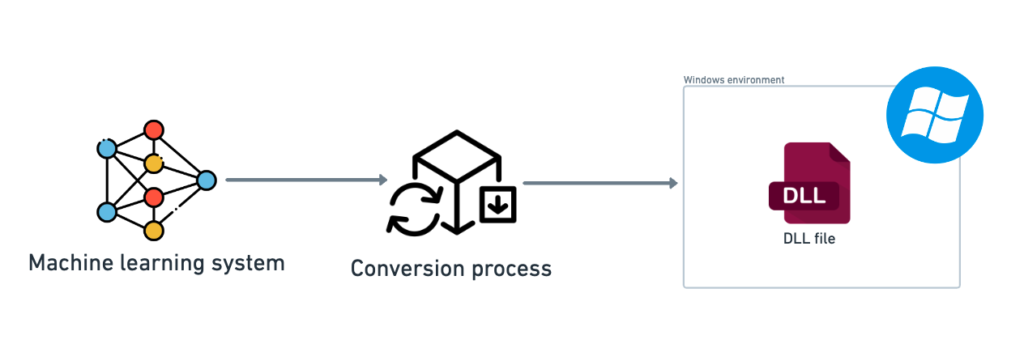
On Windows, the model can be packaged as a dynamic-link library (DLL) file. This file can be used by different programs to share code or functions without needing to rewrite them for each program.
1.2. Linux
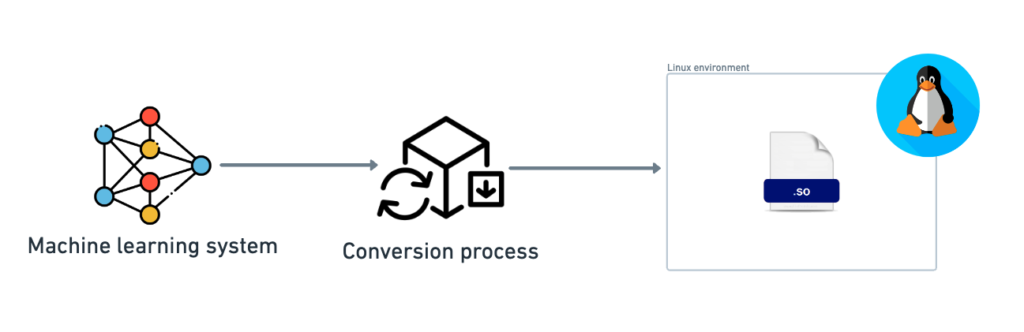
In Linux, the file used to package the model and feature extractor is a Shared Object (*.so) file, similar to a DLL on Windows.
1.3. Virtual machine-based systems
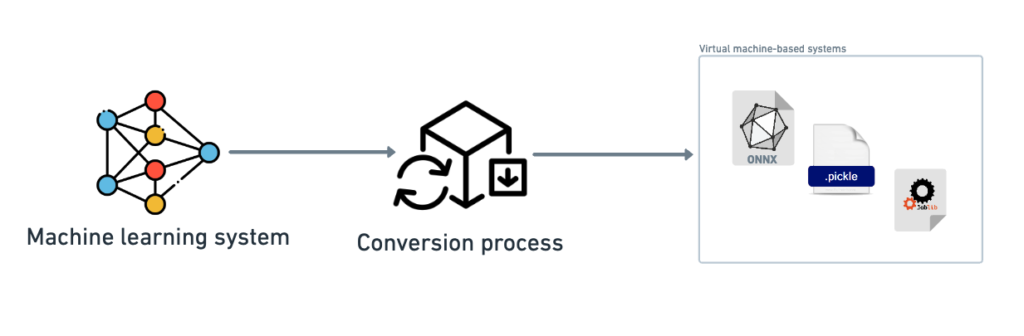
Another option is to serialize and save the packaged model in the standard resource location in virtual machine-based systems (e.g., Java or .NET). The serialization options depend on specific requirements and compatibility with the desired file format, such as .ONNX (Open Neural Network Exchange), .pickle (Python object serialization), or .joblib, as well as the intended use case and environment where the model will be deployed.
2. Benefits of static deployment
2.1. Efficiency
With static deployment, the model and the required resources are co-located, allowing for direct and consistent access. This reduces network latency and can lead to faster execution times since data doesn’t need to travel across different servers or geographical locations.
2.2. Privacy safety
Another benefit of this pattern is privacy safety, which facilitates alignment with many data protection regulations, such as LGPD or GDPR. In static deployment, user data doesn’t have to be uploaded to the server at the time of prediction. This ensures that user data is processed locally and only when necessary, making it easier for the system to comply with these regulations.
2.3. Offline prediction option
In static model deployment, the model is embedded in the same package with the other components of the system, allowing it to be used even without an internet connection. This means users can access the model’s capabilities even when they are offline, which supports compliance with data protection regulations, reduces vulnerabilities to cyber attacks, and enhances user experience with fast response times.
3. Drawbacks of static deployment
3.1. Unclear code boundaries
The line dividing the concerns between the machine learning code and the application code isn’t always clear, making it harder to update the model without upgrading the entire system.
3.2. May add complexity and confusion
Without a clear isolation of model resources and code, compared to server deployment, if the model requires specific computational resources for scoring (such as an accelerator or a GPU), it can add complexity to the entire system.
Additionally, upgrading the model or the underlying hardware in a static deployment scenario can be complicated. Static deployments typically do not support easy updates or dynamic scaling, leading to potential downtime and increased operational complexity.
4. How a static deployment looks like?
As discussed above, static deployment can follow different paths depending on the environment where the model will be deployed. In the image below, I have drawn three different paths to illustrate the various types of files the model can be converted into and the different execution environment possibilities. To gain a clear understanding of what static deployment looks like, check the image below:
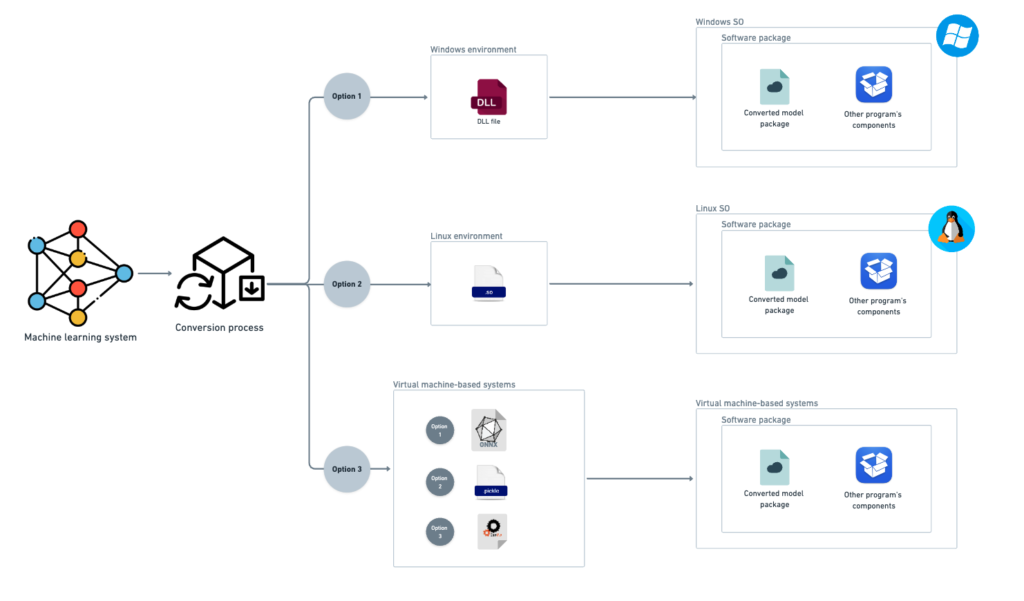
Conclusion
In the first pattern of machine learning model deployment, we discussed static deployment, the simplest pattern with several advantages such as efficiency, privacy safety, and the ability to generate offline predictions. However, this simplicity comes with drawbacks, including unclear responsibility boundaries between the machine learning code and the application code. This can lead to increased complexity and confusion during model monitoring, updating, and maintenance.
Have you ever implemented static deployment in your projects? I’m interested in hearing your thoughts or any questions you have regarding static deployment. Please share your comments, and stay tuned for the next model deployment pattern in this series.
Thank you for reading!
References
- Burkov, A. Machine Learning Engineering. 2020.
- TechTarget. “Monolithic Architecture”. Available at: https://www.techtarget.com/whatis/definition/monolithic-architecture
- Iguazio. “Static vs. Dynamic Deployment”. Available at: https://www.iguazio.com/questions/static-vs-dynamic-deployment/
- Galli, S., & Samiullah, C. Deployment of Machine Learning Models. Train in Data Team, 2024. Available at: https://www.udemy.com/course/deployment-of-machine-learning-models/
![Model deployment patterns: Dynamic deployment [2/4]](https://rodolfoteles.com.br/wp-content/uploads/2024/07/867b5dad-d9cd-4036-86b4-7dadb3ced01b-768x768.jpeg)
![Model deployment patterns: hands-on dynamic deployment using multi-containers [3/4]](https://rodolfoteles.com.br/wp-content/uploads/2024/08/b2643f06-8d28-4a10-8ac6-ce3b1406d17f-768x768.jpeg)
![Model deployment patterns: A Hands-On Guide to Dynamic Deployment on Google Kubernetes Engine [4/4]](https://rodolfoteles.com.br/wp-content/uploads/2024/12/DALL·E-2024-12-10-18.56.22-A-vibrant-and-exciting-minimalist-representation-of-orchestration-using-Kubernetes-filled-with-various-shades-of-blue.-The-design-should-emphasize-en-768x768.webp)
