
Model deployment patterns: Dynamic deployment [2/4]

In the second deployment pattern, we’ll understand the most commonly used pattern: dynamic deployment. In dynamic deployment, the model is clearly separated from the other components of the application.
This means the model can be updated without updating the entire application. This approach allows for better separation of concerns and provides more control to the data team.
Learning objectives
- Understand the components of dynamic deployment and its different versions.
- Comprehend the benefits and drawbacks of the dynamic deployment pattern.
- Visually recognize what dynamic deployment looks like.
The first version of dynamic deployment is the deployment on a virtual machine.
1. Deployment on a Virtual Machine
In dynamic deployment on a virtual machine, the machine learning system is deployed as a common web service architecture in a cloud environment, and the predictions are served through HTTP requests. [1]
A virtual machine (VM) is a simulated computing environment that operates on the physical hardware of a server. Each VM has its own operating system and can run applications as if it were an isolated physical computer.
On Google Cloud Platform, we can use Google Compute Engine to create a virtual machine (VM) cluster with a load balancer to make the VMs globally available, scale automatically, and efficiently manage traffic.
1.1. Benefits of deploying on a virtual machine
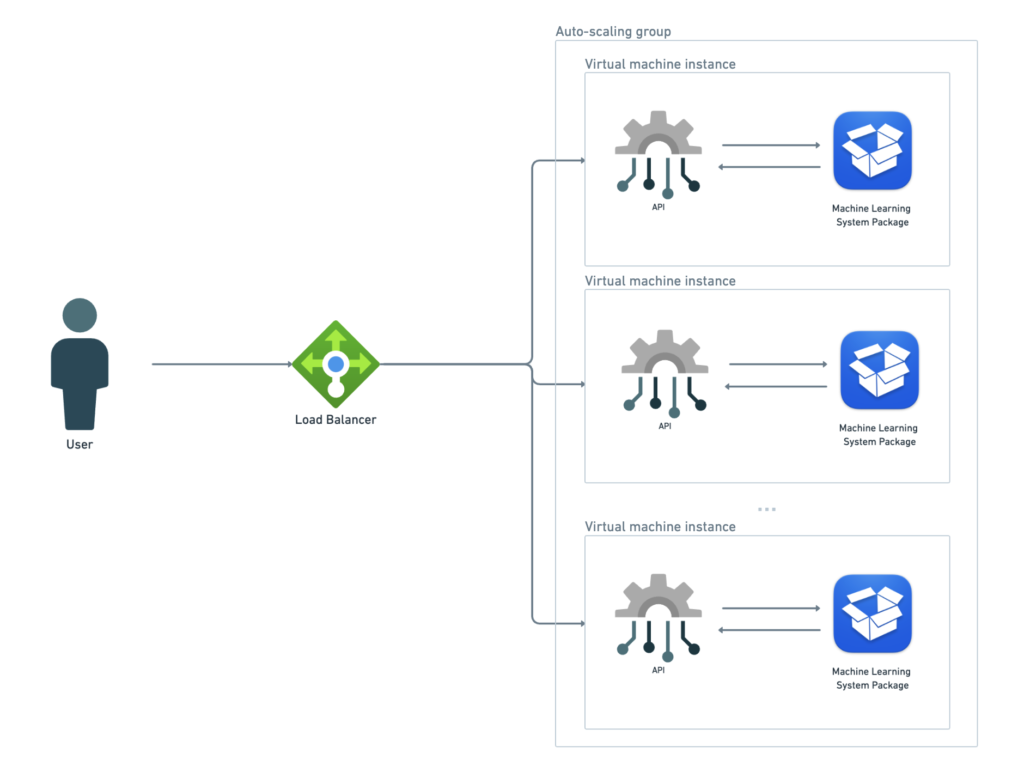
The most clear benefit of deploying on a virtual machine is the simplicity of the architecture. As you can see bellow the user’s input data are forwarded to available instance what is orchestrated by the load balancer.
The most evident benefit of deploying on a virtual machine is the simplicity of the architecture. As shown below, the user’s input data is forwarded to an available instance, orchestrated by the load balancer.
Each instance contains a replica of the machine learning system, including the feature extractor, model, and prediction script.
1.2. Cons of deploying on a virtual machine
A significant downside of using virtual machines is the need to maintain servers (physical or virtual), which typically involves higher costs.
Another con is the use of virtualization, the process of creating virtual versions of physical hardware, which adds additional computational overhead.
2. Deployment in a Container
One of the most commonly used methods for dynamic deployment is deploying a model in a container. A container is an isolated runtime environment with its own filesystem, CPU, memory, and process space, which can sometimes be confused with a virtual machine.
Typically, a container is a Docker container, but there are other alternatives such as Containerd, Podman, and CRI-O.
To distinguish between virtual machines and containers, remember that containers run on the same virtual or physical machine, sharing the same operating system, whereas virtual machines run their own instance of the operating system [1].
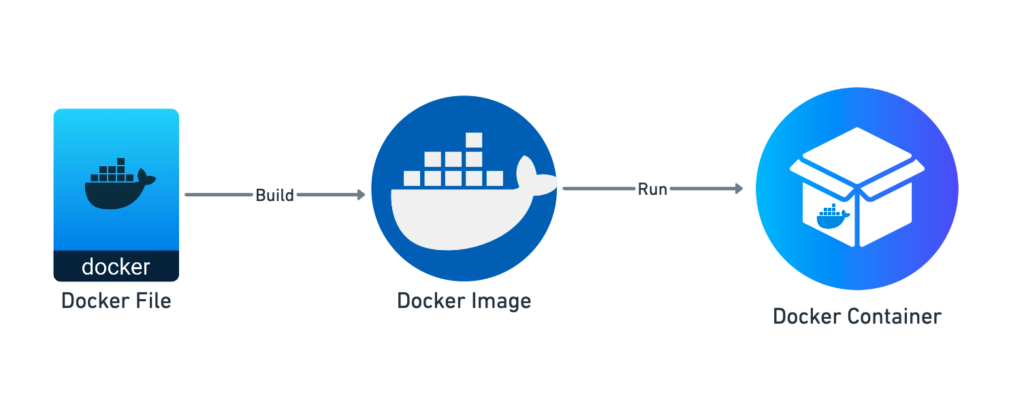
Creating a Docker container involves three main macro steps. First, you create a Dockerfile, which is a text document containing all the commands to assemble an image. Next, you build a Docker image from the Dockerfile using the docker build command.
This image is a snapshot of your application and its environment. Finally, you run a Docker container from the image using the docker run command.
The container is an instance of the image, running your application in an isolated environment.
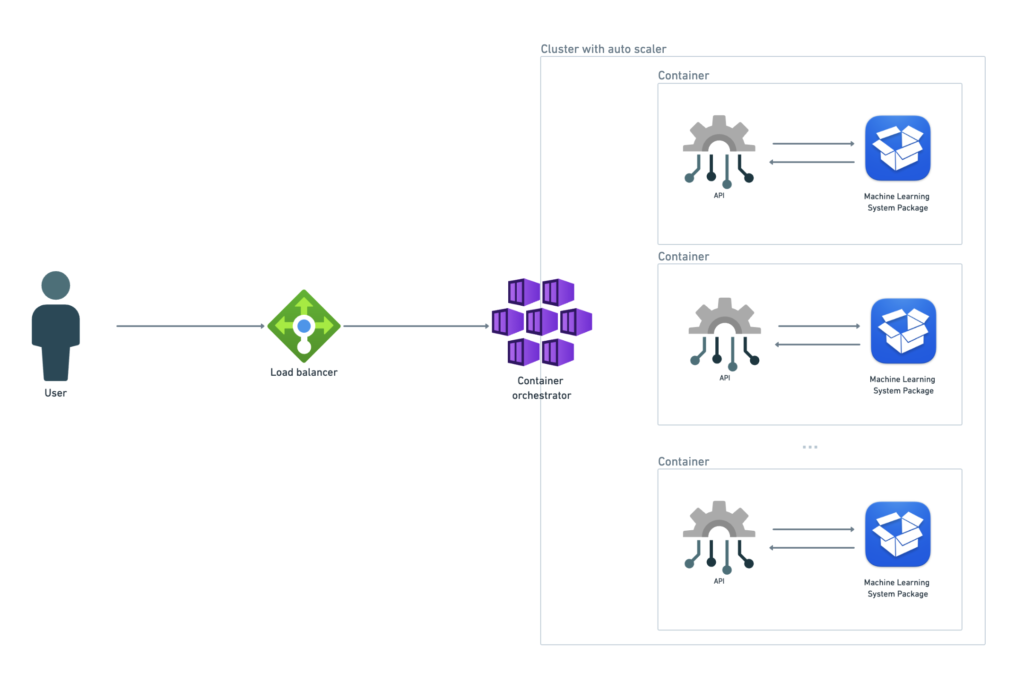
Another important aspect of deploying in a container is the ease of managing updates, rollbacks, and scaling of applications without manual intervention. This is why using container management tools is so important.
Depending on the robustness and simplicity needed for your application, you can choose to use Docker Compose or Kubernetes to orchestrate the containers. Docker Compose is suitable for simpler orchestration, while Kubernetes is designed for more advanced orchestration.
We’ll discuss these tools in more detail in upcoming posts. For now, let’s illustrate a general version of dynamic deployment.
2.1. Benefits of deploying in a container
There are three main benefits to deploying a model in a container. The first is that containers are more resource-efficient than virtual machines because multiple containers share the same host operating system kernel, reducing the overhead of running multiple OS instances. Containers can also start almost instantly since they do not need to boot a full OS.
The second benefit is the flexibility containers offer for deployment. They enable rapid and consistent deployment across various environments, including development, testing, and production.
Finally, they also allow for scaling up or down, and even scaling to zero, meaning that containerized instances can be reduced to zero when there is no demand or traffic for the application. This capability helps optimize billing cycles by incurring costs only when the application is actively being used.
2.2. Drawbacks of deploying in a container
Despite offering a resource-efficient and flexible solution for model deployment, containerized deployment has its drawbacks. The first is the complexity of configuration and integration processes.
This pattern involves using advanced tools such as Docker, Kubernetes, or cloud-based container orchestration engines like Google Kubernetes Engine or AWS Fargate , which require a solid understanding of container orchestration and management. [1]
Beyond that, proper configuration of containers is required to ensure they work seamlessly with your application and infrastructure, which can be very time-consuming.
Another drawback of deploying in a container is effective monitoring. Containers are transient resources, meaning they are destroyed when the operation is completed or the application scales down [2].
Thus, logs can be distributed across multiple instances and nodes and may be lost, making it challenging to aggregate and analyze them. Specialized logging solutions are often required to centralize and manage logs effectively.
3. Serverless deployment
The final option for dynamic model deployment is the serverless pattern. Several cloud providers offer serverless computing services, such as Google Cloud Functions, AWS Lambda, and Microsoft Azure Functions, which can be used to deploy a machine learning model [1].
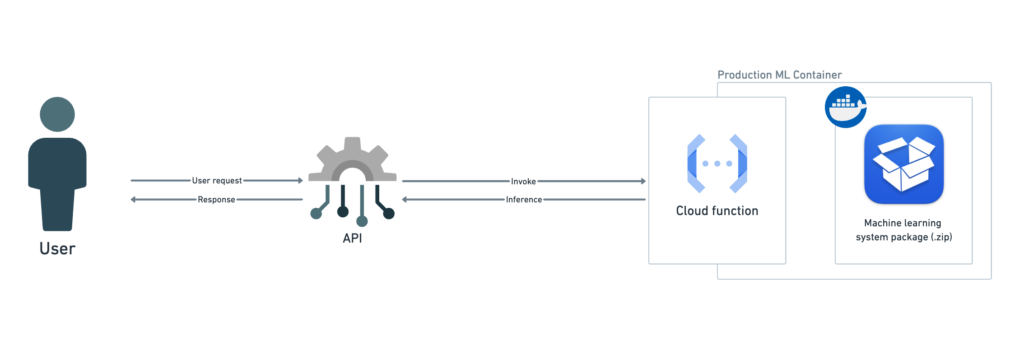
The first step is to prepare the machine learning system as a .zip file containing all necessary components: model, feature extractor, and scoring script. This compressed file must be in a specific format, which varies by cloud provider, to be correctly used as an entry point function [1].
After the machine learning system is uploaded, the cloud provider handles deploying the code and model on suitable computational resources. Users can then submit requests to the serverless function through an API.
3.1. Benefits of serverless deployment
As stated on the Google Cloud Functions page, it’s possible to “serve users from zero to planet-scale without even thinking about any infrastructure” [3]. Thus, deploying in a serverless function provides a highly scalable solution for your models.
Additionally, the ease of deployment is a major advantage since you don’t need to worry about provisioning resources such as services and virtual machines.
Given that you only pay for execution time, serverless deployment is also considered cost-efficient. Although autoscaling can be achieved with the other two deployment patterns, it often incurs noticeable latency [1].
3.2. Drawbacks of serverless deployment
A common drawback of serverless deployment is the package size limit. Depending on the complexity of your machine learning system, heavyweight dependencies can hinder deployment. For example, Google Cloud Functions has a maximum deployment size of 100MB (compressed) and 500MB (uncompressed).
Another drawback is the limited memory available during runtime. For instance, on Google Cloud Platform, the first generation has a memory limit of 8GiB, while the second generation has a limit of 32GiB.
4. Conclusion
In this post, we explored various methods of dynamically deploying machine learning systems, focusing on when to use each approach and their benefits and drawbacks.
We looked into deployment on virtual machines, which simulate physical hardware and provide isolated environments with separate operating systems.
We also examined container-based deployment, where containers offer lightweight, isolated runtime environments sharing the host OS kernel.
Lastly, we discussed serverless deployment, which uses cloud services to run ML models without managing server infrastructure.
Understanding deployment patterns and their variations enables you to derive real value from machine learning applications efficiently and effectively.
Feel free to share your thoughts or ask any questions about dynamic deployment.
References
- Machine Learning Engineering, Andriy Burkov, 2020.
- Container Monitoring Tools
- Google Cloud Functions
- A Step-by-Step Guide to Containerizing and Deploying Machine Learning Models with Docker
- Deploying Machine Learning Models with Serverless Templates
![Model deployment patterns: hands-on dynamic deployment using multi-containers [3/4]](https://rodolfoteles.com.br/wp-content/uploads/2024/08/b2643f06-8d28-4a10-8ac6-ce3b1406d17f-768x768.jpeg)
![Model deployment patterns: A Hands-On Guide to Dynamic Deployment on Google Kubernetes Engine [4/4]](https://rodolfoteles.com.br/wp-content/uploads/2024/12/DALL·E-2024-12-10-18.56.22-A-vibrant-and-exciting-minimalist-representation-of-orchestration-using-Kubernetes-filled-with-various-shades-of-blue.-The-design-should-emphasize-en-768x768.webp)
![Model deployment patterns: Static deployment [1/4]](https://rodolfoteles.com.br/wp-content/uploads/2024/07/Static_Deployment-768x768.jpeg)
